| ЖЖ » Новини » Інтернет і Технології » 2023 Январь 31 » 18:42:50 |
«Утечка» Яндекса выявила 1923 фактора ранжирования сайтов в поиске

В четверг, 26 января, стало известно, что в интернете появились исходные коды и сопутствующие им данные множества сервисов и программ «Яндекса».
SEO сообщество с небывалым энтузиазмом начало скачивать и изучать архив. Среди бесчисленного числа папок и файлов исходного кода внутреннего репозитория, общий размер данных составляет около 45 ГБ в сжатом виде, был обнаружен Search Engine and Indexing Bot, используемый поисковыми системами для ранжирования сайтов в результатах поиска.
В папке kernel.tar\web_factors_info\ был обнаружен файл с 1923 факторами ранжирования Яндекса. SEO-специалисты уже начали анализировать код, в том числе PageRank и некоторые другие факторы, связанные со ссылками.
Своими выводами при раннем анализе факторов ранжирования поделились пользователи Twitter:
- Alex Buraks создал две темы в Твиттере — первую и вторую — анализируя различные факторы ранжирования.
- Также выделим ветку в Твиттере от Mic King.
Постараемся проанализировать данные и составить собственное резюме на данную тему.
Архитектура
Чтобы понять исходный код необходимо научиться успешно его компилировать и запускать.
Как правило, новый сотрудник получает документацию и пошаговые инструкции, чтобы адаптироваться к проекту. В данном случае пресловутый архив содержит код, который везде ссылается на внутренние вики, доступа к которым нет, а комментарии в коде довольно скудны.
Сперва рассмотрим архитектуру систем ранжирования, которую предоставляет сам Яндекс в общедоступной документации.
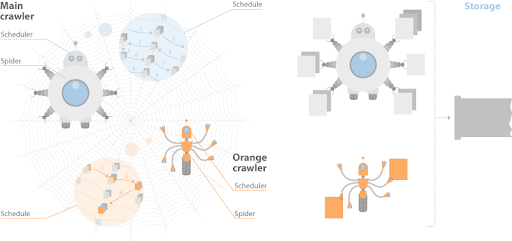
Справочник описывает двух распределенную систему краулеров
- Один для сканирования в реальном времени «Orange Crawler»,
- «Main Crawler» — для обычного сканирования.
Стоит отметить, что у Яндекса нет отдельной системы рендеринга для JavaScript. Они ограничиваются текстовым сканированием, хотя у них есть система визуального регрессионного тестирования на основе Webdriver.
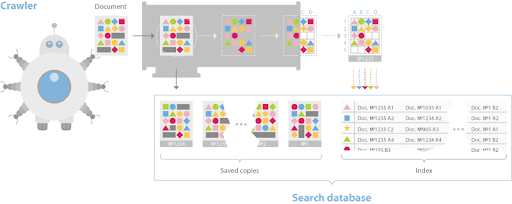
Документация также описывает сегментированную структуру базы данных, которая разбивает страницы на инвертированный индекс и сервер документов.
Как и в большинстве других поисковых систем, процесс индексации:
- создает словарь,
- кэширует страницы,
- а затем помещает данные в инвертированный индекс таким образом, чтобы были представлены биграммы и триграммы с их размещением в документе.
Однако система Яндекса также использует BERT в своем пайплайне, поэтому в какой-то момент документы и запросы конвертируются во вложения, а для ранжирования используются методы поиска ближайших соседей.
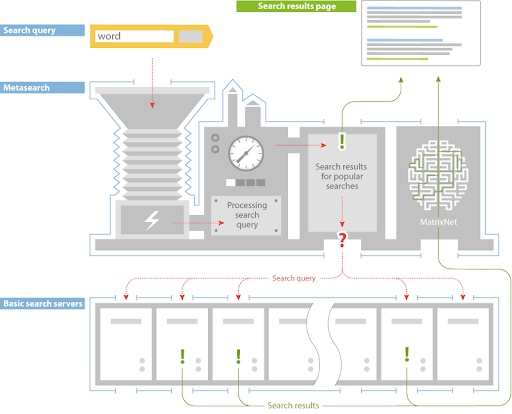
Рассмотрим непосредственно процесс ранжирования:
- В Яндексе есть слой Metasearch, где кешированные результаты популярных поисковых запросов обслуживаются после обработки запроса.
- Если результат там не найден, то поисковый запрос отправляется на несколько тысяч разных машин на уровне Basic Search одновременно.
- Каждый создает список документов для публикации, а затем возвращает его в MatrixNet – приложение нейронной сети Яндекса для повторного ранжирования
- Чтобы в конечном итоге построить поисковую выдачу.
Таким образом определение правил публикации — это первое место, на которое нам обратить внимание при изучении архива и поиска факторов ранжирования.
Вероятно факторов ранжирования намного больше
При изучении кода большинство специалистов анализировали файл web_factors_info/factors_gen.in. из архива Kernel. Он и содержит 1922 фактора ранжирования.
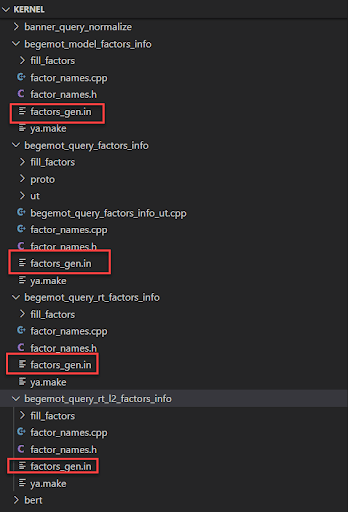
При более глубоком изучении архива можно заметить, что существует множество файлов с факторами ранжирования для различных систем обработки запросов.
Более того Яндекс уточняет, что у них есть три класса факторов ранжирования:
- статические,
- динамические
- те, которые связаны конкретно с поиском пользователя и тем, как он был выполнен.
В архиве они указаны в файлах с тегами TG_STATIC и TG_DYNAMIC. Факторы, связанные с поиском, имеют несколько тегов, таких как TG_QUERY_ONLY, TG_QUERY, TG_USER_SEARCH и TG_USER_SEARCH_ONLY.
Подводя итоги мы выявили более 18 000 потенциальных факторов ранжирования. Вы можете посмотреть данный список по ссылке
Веса факторов ранжирования
Файл nav_linear.h в каталоге /search/relevance/ содержит веса, связанные с факторами ранжирования. Коэффициенты показывают, насколько важен каждый фактор, а результирующая сумма будет использоваться для оценки релевантности страниц.
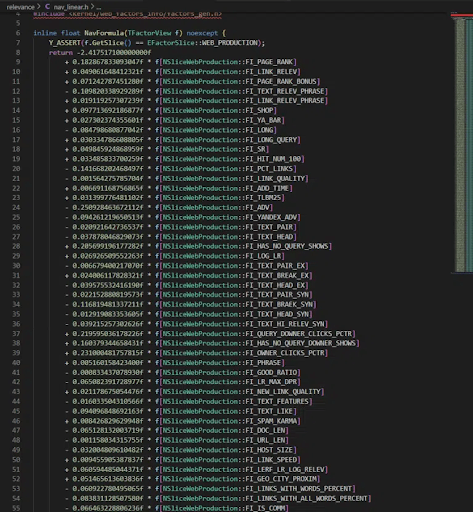
Конечно, это не единственное место, где происходит ранжирование. Данная функция, скорее всего, используется для создания списков, которые впоследствие передаются в MatrixNet для сравнения.
В опубликованном архиве есть множество ссылок на MatrixNet и «mxnet», а также на DSSM.
В описании одного из факторов ранжирования FI_MATRIXNET указано, что MatrixNet применяется ко всем факторам.

Также есть куча бинарных файлов, которые сами могут быть предварительно обученными моделями.
Однако сразу становится ясно, так это то, что существует несколько уровней ранжирования (L1, L2, L3) и существует набор моделей ранжирования, которые можно выбрать на каждом уровне.
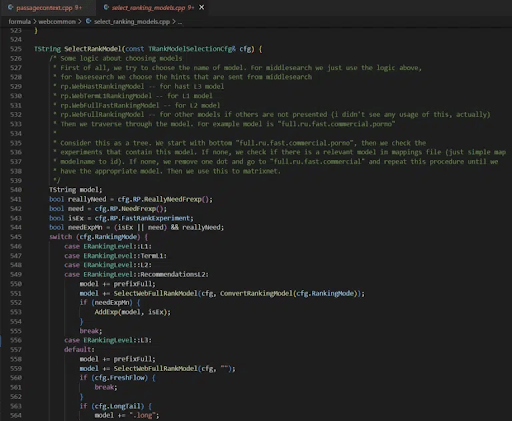
В файле selection_rankings_model.cpp предполагается, что на каждом уровне процесса можно рассматривать разные модели ранжирования.
Примерно так работают нейронные сети. Каждый уровень — это аспект, который дает переранжированный список документов. Именно он в конечном итоге отображается в виде поисковой выдачи.
К чему мы затеяли весь этот анализ?
Список факторов ранжирования содержит тег TG_DEPRECATED, который вероятно классифицирует его как неиспользуемый. Сменим фокус от этого предположения, и отсортируем факторы по степени влияния
Топ-5 отрицательных факторов ранжирования
- FI_ADV: -0,2509284637 — этот фактор определяет на странице рекламу любого рода, и назначает самый высокий штраф.
- FI_DATER_AGE: -0,2074373667 — этот коэффициент представляет собой разницу между текущей датой и датой документа.
- Значение равно 1, если дата документа совпадает с сегодняшней,
- 0, если документ старше 10 лет или если дата не определена.
Яндекс отдает предпочтение более старому контенту.
- FI_QURL_STAT_POWER: -0,1943768768 — этот коэффициент представляет собой количество показов URL, связанного с запросом.
Похоже, что яндекс понижает наиболее частый URL, тем самым увеличивает разнообразие результатов.
- FI_COMM_LINKS_SEO_HOSTS: -0,1809636391 — процент входящих ссылок с «коммерческим» анкором.
Фактор ремапится на [0,1] если доля таких ссылок > 50%, иначе 0
- FI_GEO_CITY_URL_REGION_COUNTRY: -0,168645758 — географическое совпадение документа и страны, из которой пользователь выполнял поиск (ip или lr). Актуально для России и Украины.
Таким образом, для наилучшего результата вы должны:
- Избегать рекламы.
- Обновлять старый контент, а не создавать новые страницы.
- и еще, Яндекс любит анкорные ссылки.
Топ-5 положительных факторов ранжирования
- FI_URL_DOMAIN_FRACTION: +0.5640952971 — этот фактор представляет собой покрытие домена трехбуквиями из запроса. Простыми словами: мы сравниваем запрос и URL выдачи.
Пример: Челябинская лотерея – chelloto. Переводим запрос в транслит, находим трехбуквия которые покрываются (che, hel, lot, olo), смотрим какую долю от всех трехбуквиев покрыли
- FI_QUERY_DOWNER_CLICKS_COMBO: +0.3690780393 — “фактор, хитрым образом скомбинированный из FRC и псевдо-CTR”. Непосредственных указаний на то, что такое FRC, нет.
- FI_MAX_WORD_HOST_CLICKS: +0.3451158835 — кликабельность самого важного слова в домене. Например, для всех запросов, в которых есть слово «википедия», кликают на страницы википедии.
- FI_MAX_WORD_HOST_YABAR: +0.3154394573 — «Наиболее характерное слово запроса, соответствующее сайту, по данным бара».
Предполагаем, что это означает ключевое слово, которое чаще всего ищут при помощи Yandex Toolbar.
- FI_IS_COM: +0.2762504972 — Домен в зоне .com
Другими словами:
- Уделите внимание правилам построения URL.
- А также сравните вхождение ключевых слов с ожидаемым результатом
У Яндекса есть верхние границы для некоторых факторов ранжирования
315 факторов ранжирования имеют пороговые значения. Если анализируемый URL его превышает, система считает страницу чрезмерно оптимизированной
Ручное управление ранжированием
В общем механизме могут присутствовать искусственные улучшения определенных документов, чтобы обеспечить более высокие позиции.
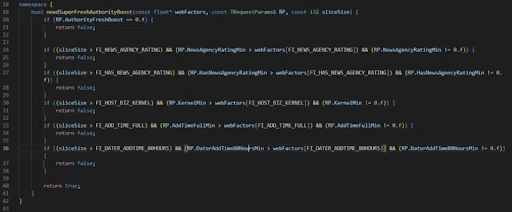
Например, в переменных упоминается NEWS_AGENCY_RATING, что говорит о намеренном завышении score в пользу новостных сайтов.
Поведенческие факторы имеют большое значение
Многие факторы ранжирования связаны с поведением пользователей, такие как высокий CTR, last-click, время на сайте и показатель отказов.
Согласно опубликованной базе эти факторы оказывают гораздо большее влияние на ранжирование в Яндексе, чем можно подумать. Важно следить за поведением пользователей на вашем сайте и при необходимости вносить улучшения.
Ссылочные факторы
Калькулятор ссылочного спама Яндекса учитывает 89 факторов. Все, что помечено как SF_RESERVED, устарело (Общий список размещен ссылке)
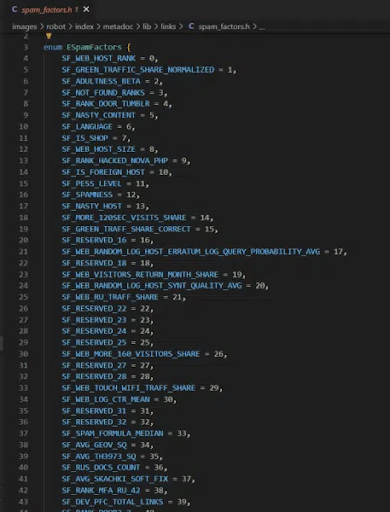
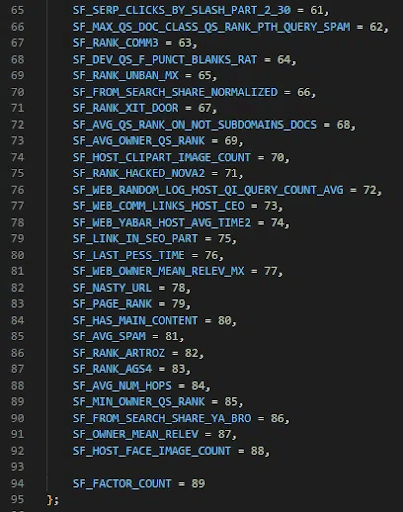
У Яндекс есть host-рейтинг, который хранит спам-сайты в течение длительного времени.
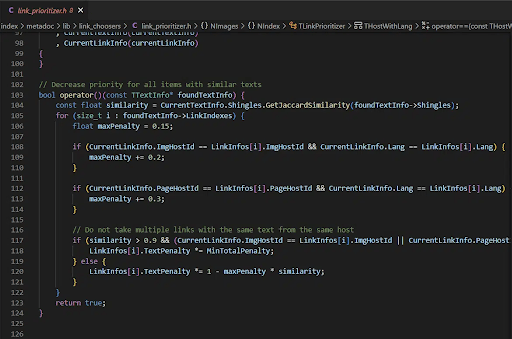
Система также анализирует дубликаты страниц, а также ссылки с одинаковым анкорным текстом с одного и того же сайта.
Это говорит нам о том, нужно учитывать сколько ссылок размещено из одного и того же источника. Важно ориентироваться на уникальные ссылки из большего количества источников.
Тэги: